
🎯 프로젝트 목표
우리 서비스에서 사용자에게 제공하는 비즈니스 로직으로 인해, 우리 서비스 내부에서만 확인할 수 있는 데이터가 있다.
해당 데이터를 활용해 제공할 수 있는 또 다른 기능이 다른 서비스로 확장되면서 다른 서비스에서 우리 서비스와 데이터를 동기화 할 필요가 생겼다. 그래서 이벤트를 발행해 우리 서비스 데이터의 새로운 업데이트가 생기면 다른 서비스에서 구독해서 데이터를 동기화하였다.
이러한 흐름에서, 두 서비스의 데이터가 일치하지 않으면 즉각 발견하고 대응할 필요가 생겼다. 이 니즈를 해결하기 위해 알림 시스템을 사용하고, 알림을 발생시키기 위한 지표를 수집해야한다.
이에 따라 지속적으로 현재 우리 서비스의 상태값과 해당 서비스의 상태값이 일치하는 지 확인하는 업무를 맡게 되었다.
🤔 구현 방식
알림을 발생시키기 위해서는 알림을 트리거 할 '조건'이 필요하다.
조건을 만들기 위해서는 지속적으로 현재 상태를 모니터링할 수 있는 '지표'가 필요하다.
따라서 아래 흐름으로 구현을 하는 것을 계획하였다.
1. 우리 서비스의 상태 값을 모니터링하는 지표를 생성한다.
2. 우리 서비스와 다른 서비스의 데이터가 불일치함을 감지할 수 있는 조건을 만든다.
3. 조건이 트리거되었을 때 알림을 발생할 수 있도록 설정한다.
⚒️ 기술 스택
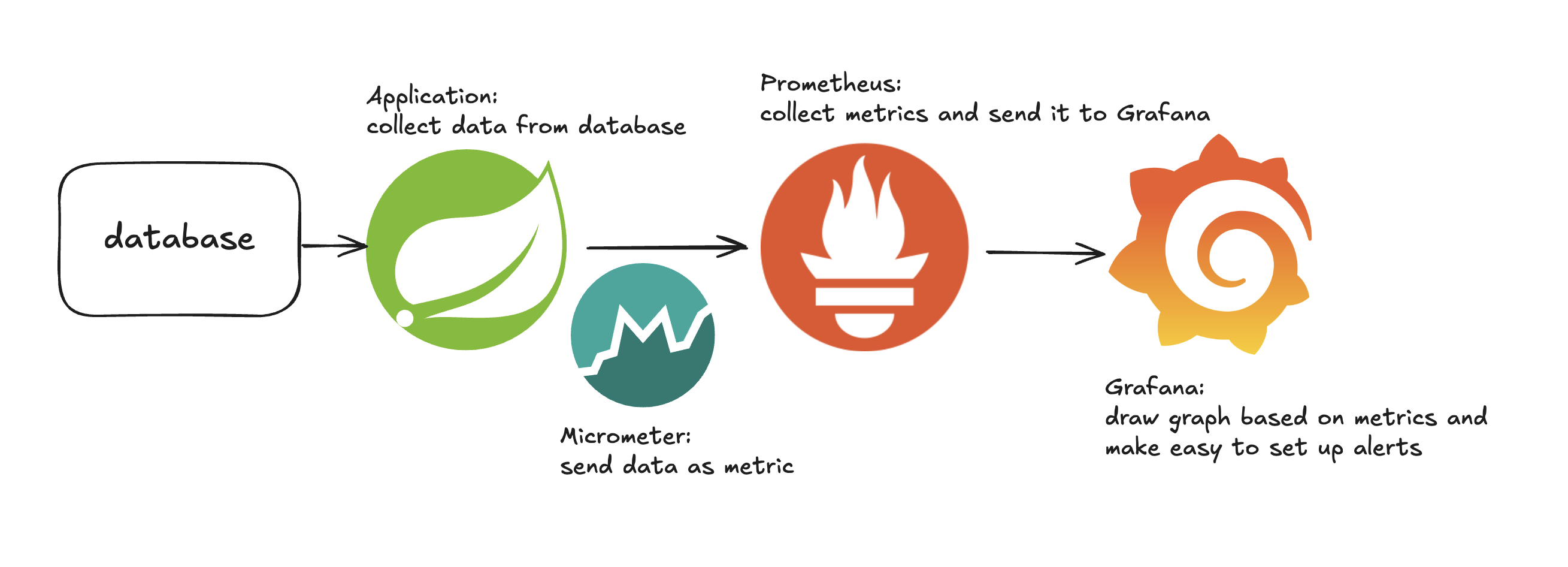
Backend Application 데이터베이스와 연결되어 필요한 형태로 데이터를 수집하고 가공한다.
Micrometer 백엔드 애플리케이션과 연결되어 가공된 데이터를 프로메테우스로 전송하는 역할을 한다.
Prometheus 마이크로미터와 연결되어 데이터를 지표로서 수집하고 그라파나로 전송한다.
Grafana 전송된 지표와 설정된 알림을 시각적으로 보여준다. 불일치가 발생하였을 때 자동으로 이를 트리거하고 알림을 발생시킬 수 있다.
👩💻 구현 과정
도메인을 이해하고 지표로 보낼 데이터 만들기
애플리케이션 레벨에서 가장 쉬운 것부터 시작했다.
먼저 타 서비스로 발행하는 이벤트가 무엇이고 어떤 형태이며, 어떤 시점에서 발행되는 지 조사했다. '이벤트가 실패하지 않았고 데이터 동기화가 완료되었음'을 확인하는 지표를 만들기 위해서 이벤트의 목적을 파악해야했기 때문이다.
한 명의 사용자가 상태 A에서 상태 B로 전환된 상황에서 이벤트가 발행된다고 가정하면, 상태 B인 사용자가 총 몇 명인지 확인할 수 있는 데이터베이스 쿼리를 디자인하였다.
이를 통해 '상태 B인 사용자 수'를 비교하여 두 서비스 간의 데이터 동기화가 잘 되고 있음을 확인하도록 하였다.
Micrometer를 사용해 Prometheus로 지표 전송하는 코드 작성
이제 데이터베이스 쿼리로 수집한 값을 지표로 전송한다.
Micrometer는 MeterRegistry를 사용해 애플리케이션 내에 지표를 관리한다.
MeterRegistry를 빈 등록하고 아래 세 가지 옵션 중 하나를 선택해서 지표를 추가할 수 있다.
Counter counter = registry.counter("counter");
AtomicInteger myGauge = registry.gauge("numberGauge", new AtomicInteger(0));
Timer timer = Timer.builder("my.timer").register(registry);
지표의 성격에 따라 Counter, Gauge, Timer 중에 하나를 선택해야 한다.
- Counter는 일정하게 증가하는 성격의 지표일 때. 예를 들어 총 배달 횟수와 같이 항상 양수이며 증가만 하는 지표이다.
- Gauge는 현재 상태를 모니터링하는 성격의 지표일때. 예를 들어 현재 접속사 수와 같이 증가하고 줄어들기도 하는 지표이다.
- Timer는 짧은 시간의 Latency를 측정하거나 특정 이벤트의 주기를 계산하기 위한 지표이다.
특정 상태인 사용자의 총합을 지표로 사용하고 있기 때문에, 사용자마다 상태가 지속적으로 변화함에 따라 Gauge 지표를 사용해 현재 총 합을 모니터링할 필요가 있었다.
하지만 기존 지표들은 모두 Counter 지표였으며 이를 기반해 설계되어있었다. 그래서 Gauge 지표를 전송하기 위한 시스템을 도입해야했고, 다루기 까다로웠던 포인트가 세가지 있었다.
🤦♀️ 메모리를 모니터링해서 지표 값을 업데이트하는 Gauge의 특이한 시스템
meterRegistry.counter(metricName, tags).increment(amount)
Counter의 경우 해당 코드를 반복호출해서 일정 amount만큼 증가하였음을 지표로 전송하는 시스템이다.
그러나 Gauge의 경우 Micrometer가 지속적으로 애플리케이션 메모리를 모니터링하고, 메모리 값의 변화가 생기면 Prometheus로 바뀐 값을 전송한다. 이를 하이엔-게이지 (Heisen-gauge) 라고 한다. 코드로 설명해보자.
private val gaugeMetric = AtomicDouble()
Micrometer가 모니터링할 메모리를 할당하기 위해 변수를 선언했다.
meterRegistry.gauge(metricName, tags, amount)
해당 변수가 앞으로 모니터링될 수 있게 gauge 함수를 사용해서 Micrometer에 등록한다. 이제 이 변수는 애플리케이션이 살아있는 동안 모니터링된다.
gaugeMetric.increment()
gaugeMetric.decrement()
지표값에 변화가 생기는 비즈니스 로직에 위와 같이 지표를 증가/감소 시킨다. 혹은 아예 새로운 값으로 변경하고 싶다면 아래와 같이 변수의 값을 바꾼다.
gaugeMetric.set(20)
이렇게 하면 자동으로 Micrometer가 변화를 감지해 Prometheus에게 변화된 지표를 전송한다.
🤦♀️ 원시값이 아닌 객체를 사용해서 변수를 선언해야하는 점
Gauge 지표를 사용할 때는 변수를 Double, Integer 처럼 원시값이 아닌 AtomicDouble, AtomicInteger을 사용해주어야 한다. 왜냐하면 원시값의 값을 참조하는 것이 아니라, 객체의 주소를 참조해야하기 때문이다. 원시값으로 복사해서 등록하게 되면 값의 변경을 감지할 수 없다. 하지만 주소를 참조한다면 값의 변경을 감지해 지표를 갱신할 수 있다.
🤦♀️ 애플리케이션 재시작마다 지표가 초기화된다는 점
어느 시점에서 지표를 전송할 것이냐? 라는 고민을 하였다. 원래 계획은 사용자의 상태가 변화할 때마다 지표를 전송하는 것이었다.
하지만 배포 등으로 애플리케이션이 재시작 될때마다 메모리가 초기화되어버리니, 매번 현재 지표값을 계산해서 등록해야했다. 따라서 하루에 한 번씩 특정 상태에 있는 사용자 수를 데이터베이스에서 계산한 다음 지표로 보내는 작업을 Job에 추가했다.
왜냐하면 두 서비스 간의 현재 지표값의 싱크를 맞추는 일은 하루에 한번이면 충분하고, 사용자의 상태가 변할 때마다 재계산해서 지표를 보내는 것은 과하다는 판단에 의해서이다.
Gauge를 다루는 것은 까다롭고 복잡했다. 이미 Gauge를 도입한 다른 팀 코드를 참고하면서 여러 번 테스트했다.
지표 보내는 작업을 Job에 추가한 것이 원인이 되어 다른 문제가 생겼다.
🦈 Job 실행 이후에도 지표가 전송되지 않은 문제
Job에 지표를 전송하는 코드를 추가했다. 근데 이상하게 Job이 성공적으로 끝나도 지표는 전송되지 않았다. 원인을 파악하기 위해 프로메테우스 로그를 확인하거나 애플리케이션 로직에 로그를 추가해 문제가 생기는 부분을 파악해보았다.
다양한 가설을 세워 접근한 끝에 원인을 찾을 수 있었다. Prometheus에게 지표를 pulling 방식으로 가져온다. 그러나 지표 전송 직후 Job이 종료되기 때문에 지표가 전송되지 않은 것이었다.
따라서 Prometheus PushGateway를 도입하였다. Pull 방식이 아닌, HTTP 요청으로 직접 지표 정보를 Push하여 Prometheus와 연결된 PushGateway로 지표를 전송한다. 이 경우 Job이 즉시 종료되어도 데이터는 PushGateway에 남아있기 때문에, Prometheus가 안전하게 지표를 수집해갈 수 있다.

Prometheus PushGateway를 사용하는 방법은 다음과 같다.
spring:
config:
activate:
on-profile:
- profile_name
management:
metrics:
export:
prometheus:
pushgateway:
enabled: true
base-url: ${PROMETHEUS_PUSH_GATEWAY_URL:localhost:9091}
job: job_name
push-rate: 2s
shutdown-operation: push
이렇게 하면 특정 profile에 속한 job에 대해 PushGateway를 사용해 지표를 전송할 수 있다.
하지만 이러한 방식을 사용할 때는 주의가 필요하다고 한다.
- 여러 인스턴스가 사용하는 경우 PushGateway가 단일 장애 지점이 될 수 있다.
- 오래된 메트릭을 자동으로 지우지 않고 영구적으로 보관한다. 인스턴스의 생명주기와 별도로 동작하기 때문에 예상치 못한 에러를 발견할 수 있다.
지표를 활용한 알림 생성하기
사실 나는 메트릭 시스템을 다뤄본 적이 없어 그라파나를 사용해서 지표를 확인하는 것도 어려웠다. 알림을 생성하기 위해 지표를 확인하고 알림 조건을 작성하는 방법에 대해 알아보았다.
그라파나 대시보드로 지표 관찰하기

위와 같은 Metric browser를 사용해 원하는 지표를 탐색하고, 적절하게 Label을 설정해서 그래프를 관찰하였다.
알림 대시보드 확인하기
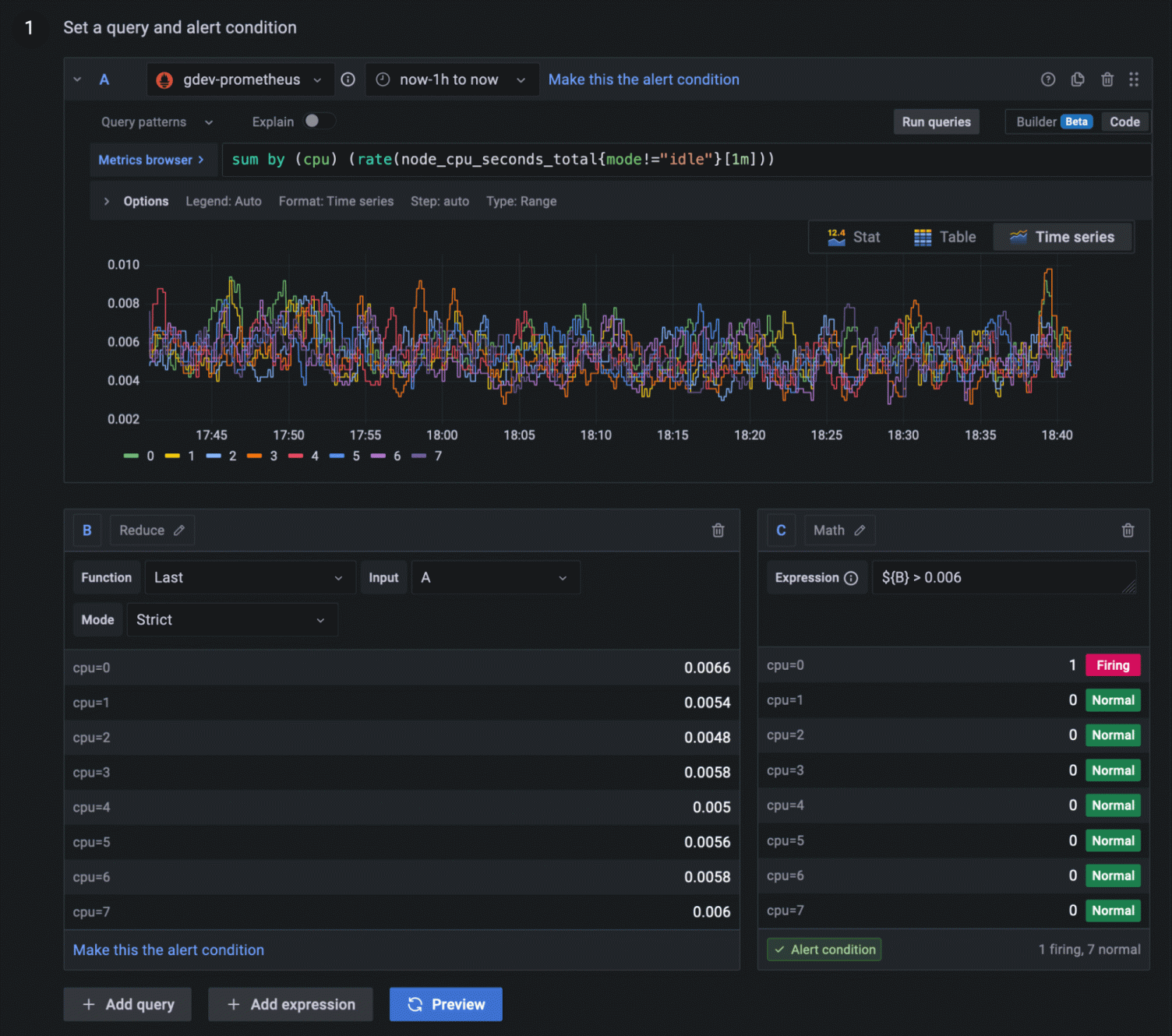
위 사진은 알림 설정 예시화면이다. sum by 등의 쿼리문을 활용해 알림 조건을 설정하는 것을 볼 수 있다.
지표를 사용해서 두 서비스 간의 지표 값의 불일치 발생 시 알림을 발생시키도록 쿼리를 생성해보자.
알림 조건을 위한 쿼리 구현하기
프로메테우스의 지표를 사용해 쿼리를 구현하기 위해서는 PromQL (Prometheus Query Language) 을 익혀야한다. PromQL에 대한 자세한 내용은 여기서 확인할 수 있다.
우리 서비스의 지표 값과 다른 서비스의 지표 값을 비교해서 차이가 발생했을 때 알림을 트리거하는 조건 예시이다.
abs(sum(우리_서비스의_지표_이름) - sum(다른_서비스의_지표_이름)) > 5sum(우리_서비스_지표_이름) > sum(다른_서비스_지표_이름) * 0.3
이런 식으로 간단한 산수를 사용해 동기화가 되지 않은 상황을 트리거 할 수 있다.
사실 실제로 돌아가는 알림 조건들을 보면 이렇게 간단하지 않고, 다양한 변수를 고려해 작성한다.
(
abs(
A - B
)
/ B
) > 0.5 and B > 10
하나의 예시를 보자. 이 또한 동기화 상태에서 벗어난 걸 감지하는 쿼리이다.
A와 B의 차이가 기준값의 50% 이상인 경우, 그리고 지표 B의 값이 유의미한 양일 때 (10 이상) 알림을 발생한다.
임계조건을 설정하여 의미있는 비교를 하고, 너무 적은 수치일 때 노이즈가 생기는 현상을 방지할 수 있는 쿼리이다.
이런 식으로 알림까지 생성해주면 프로젝트 목표는 달성이다. 🎉
🎉 프로젝트 후기
지표를 설정하고, 이를 사용해서 알림을 생성하는 단순해보이는 과제다. 하지만 팀의 코드베이스에서 지표를 전송하는 흐름을 이해하고, 처음 써보는 그라파나 대시보드 사용에 익숙해지고, 지표를 사용해 직접 쿼리도 작성해야 했다. 더욱이 Gauge라는 다소 까다로운 친구를 다루고자 노력하는 과정이 필요했다.
뿐만 아니라 우리 서비스와 다른 서비스가 어떤 방식으로 상호작용하고 있는 지 이해하였다. 그리고 적절한 값을 지표로 전송하기 위해 데이터베이스에 어떤 쿼리를 날려 데이터를 수집할 지 고민하면서 도메인에 대한 이해도를 키울 수 있었다. 추가로 쿠버네티스 pod이나 job을 다루기 위한 기본적인 명령어를 익힐 수 있었다.
아는 것이 거의 0이었던 시점에서 시작해서 이 프로젝트로 인해 도메인 이해, 코드 베이스 이해, 그라파나 사용에 대한 이해, 우리 서비스의 지표 시스템에 대한 이해를 할 수 있었다. 익숙하지 않은 것 투성이라 한 발 내딛을 때마다 막히는 느낌을 받았지만, 끝까지 잘해냈다고 생각해서 뿌듯하다. 👊
참고
https://docs.micrometer.io/micrometer/reference/concepts/gauges.html
Gauges :: Micrometer
Micrometer supports one last special type of Gauge, called a MultiGauge, to help manage gauging a growing or shrinking list of criteria. This feature lets you select a set of well-bounded but slightly changing set of criteria from something like an SQL que
docs.micrometer.io
https://prometheus.io/docs/practices/pushing/
When to use the Pushgateway | Prometheus
Prometheus project documentation for When to use the Pushgateway
prometheus.io
https://grafana.com/docs/grafana/latest/alerting/fundamentals/alert-rules/queries-conditions/
Queries and conditions | Grafana documentation
Grafana Cloud Enterprise Open source Queries and conditions In Grafana, queries fetch and transform data from data sources, which include databases like MySQL or PostgreSQL, time series databases like Prometheus or InfluxDB, and services like Amazon CloudW
grafana.com
'업무 > 기술회고' 카테고리의 다른 글
| 이벤트 발행/구독 모델을 활용한 실시간 데이터 동기화 feat. AWS SNS, SQS (4) | 2025.08.04 |
|---|